
linux ( as well as most of the unixes ) provides the ability to integrate many different file systems at the same time. to name a few of them:
- ext2, ext3, ext4
- ocfs, ocfs2
- reiserfs
- vxfs
- brtfs
- dos, ntfs
- …
although each of them provides different features and was developed with different purposes in mind the tools to work with them stay the same:
- cp
- mv
- cd
- …
the layer which makes this possible is called the virtual filesystem ( vfs ). this layer provides a common interface for the filesystems which are plugged into the operating system. I already introduced one special kind of filesystem, the the proc filesystem. the proc filesystem does not handle any files on disk or on the network, but neitherless it is a filesystem. in addition to the above mentioned filesystems, which all are disk based, filesystem may also handle files on the network, such as nfs or cifs.
no matter what kind of filesystem you are working with: when interacting with the filesystem by using the commands of choice you are routed through the virtual filesystem:
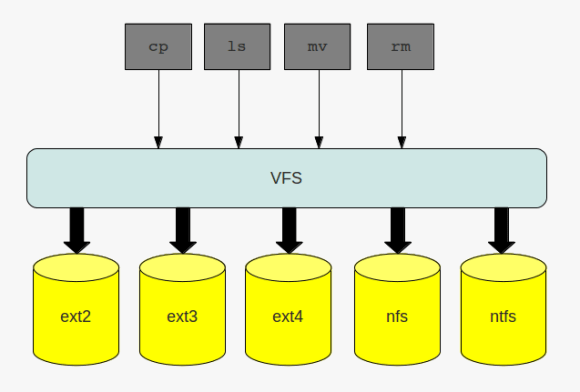 the virtual file system
the virtual file system
to make this possible there needs to be a standard all file system implementations must comply with, and this standard is called the common file model. the key components this model consist of are:
- the superblock which stores information about a mounted filesystem ( … that is stored in memory as a doube linked list )
- inodes which store information about a specific file ( … that are stored in memory as a doube linked list)
- the file object which stores information of the underlying files
- dentries, which represent the links to build the directory structure ( … that are stored in memory as a doube linked list)
to speed up operations on the file systems some of the information which is normally stored on disk are cached. if you recall the post about slabs, you can find an entry like the following in the /proc/slabinfo file if you have a mounted ext4 filesystem on your system:
cat /proc/slabinfo | grep ext4 | grep cache ext4_inode_cache 34397 34408 920 17 4 : tunables 0 0 0 : slabdata 2024 2024 0
so what needs the kernel to do if, for example, a request for listing the contents of a directoy comes in and the directory resides on an ext4 filesystem? because the filesystem is mounted the kernel knows that the filesystem for the specific request is of type ext4. the ls command will then be translated ( pointed ) to the specific ls implementation of the ext4 filesystem. this operation is the same for all commands interacting with filesystems. there is a pointer for each operation that links to the specific implementation of the command in question:
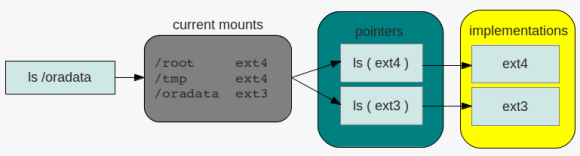 directory listing
directory listing
as the superblock is stored in memory and therefore may become dirty, that is not synchronized with the superblock on disk, there is the same issue that oracle must handle with its buffer pools: periodically check the dirty flag and write down the changes to disk. the same is true for inodes ( while in memory ), which contain all the information that make up a file. closing a loop to oracle again: to speed up searching the ionodes linux maintains a hash table for fast access ( remember how oracle uses hashes to identify sql statements in the shared_pool ).
when there are files, there are processes which want to work with files. once a file is opened a new file object will be created. as these are frequent operations file objects are allocated through a slab cache.
the file objects itself are visible to the user through the /proc filesystem per process:
ls -la /proc/*/fd/ /proc/832/fd/: total 0 dr-x------ 2 root root 0 2012-05-18 14:03 . dr-xr-xr-x 8 root root 0 2012-05-18 06:40 .. lrwx------ 1 root root 64 2012-05-18 14:03 0 -> /dev/null lrwx------ 1 root root 64 2012-05-18 14:03 1 -> /dev/null lr-x------ 1 root root 64 2012-05-18 14:03 10 -> anon_inode:inotify lrwx------ 1 root root 64 2012-05-18 14:03 2 -> /dev/null lrwx------ 1 root root 64 2012-05-18 14:03 3 -> anon_inode:[eventfd] lrwx------ 1 root root 64 2012-05-18 14:03 4 -> /dev/null lrwx------ 1 root root 64 2012-05-18 14:03 5 -> anon_inode:[signalfd] lrwx------ 1 root root 64 2012-05-18 14:03 6 -> socket:[7507] lrwx------ 1 root root 64 2012-05-18 14:03 7 -> anon_inode:[eventfd] lrwx------ 1 root root 64 2012-05-18 14:03 8 -> anon_inode:[eventfd] lrwx------ 1 root root 64 2012-05-18 14:03 9 -> socket:[11878] ...
usually numbers 0 – 3 refer to the standard input, standard output and standard error of the corresponding process.
last but not least there are the dentries. as with the file objects, dentries are allocated from a slab cache, the dentry cache in this case:
cat /proc/slabinfo | grep dentry dentry 60121 61299 192 21 1 : tunables 0 0 0 : slabdata 2919 2919 0
directories are files, too, but special in that kind that dictories may contain other files or directories. once a directory is read into memory it is transformed into a dentry object. as this operation is expensive there is the dentry cache mentioned above. thus the operations for building the dentry objects can be minimized.
another link to oracle wording: the unused dentry double linked list uses a least recently used ( lru ) algorithm to track the usage of the entries. when the kernel needs to shrink the cache the objects at the tail of the list will be removed. as with the ionodes there is hash table for the dentries and a lock protecting the lists ( dcache_spin_lock in this case ).
this should give you enough hints to go further if you are interesed …

