nowadays everybody is talking about consolidation to reduce costs and ( maybe ) to simplify management of the infrastructure. the current trend seems to be:
- buy big boxes ( exadata, for example ) and put many databases on one physical host.
- buy big boxes, use one of the virtualization or partition technologies ( vmware, lpars, ldoms, oracle vm, solaris zones, …. ) and put the database on the virtual hosts
- use RAC in combination with cheaper boxes and try to scale by adding more cheaper boxes once the workload increases
what less people seem to think about ( correct me if I’m wrong ): why not consolidate some of the smaller applications which do not need that much resources into the same database ? this will reduce licensing costs and ( maybe ) simplifies administration, too. of course, there are things to consider:
- each application must use the same database version
- if you need to patch, all applications will be affected
- if you need to upgrade, all applications will be affected
- if there is unplanned or planned downtime, all applications will be affected
- security inside the database becomes more important: permissions, roles …
- if one of the applications goes crazy how do you manage that it does not affect the other applications that much that they are not usable anymore ?
- how to quickly identify an application which has troubles ?
having thought about these points maybe you’ll give it a try. especially for identifying the applications quickly and react on issues one concept that should be implemented is services. if you ever worked with RAC, services should not be new to you, but services are useful in single instances, too. as services do not require any changes to the application implementing them is straight forward:
- if you use oracle restart or a clustered grid infratructure the easiest way to manage services is by using the srvctl utility
- if you don’t use oracle restart, single instance services should be managed by the dbms_service package
this post will discuss both methods and give some examples. obviously the first step you need to do is to create a service ( I will create two services to show how one can connect to a specific service later ).
the srvctl way:
srvctl add service -d DB112 -s BEER -y AUTOMATIC -B SERVICE_TIME
… where:
- -d: is the database unique name
- -s: is the service name
- -y: is the flag for the management policy
- -B: is the runtime load balancing goal
note: there are some other parameters one can specify, but as these parameter are important for failover, load balancing, dataguard and rac I will not discuss them right now.
service created. does oracle restart report the newly created service ? yes, of course:
crsctl stat res ora.db112.beer.svc
NAME=ora.db112.beer.svc
TYPE=ora.service.type
TARGET=OFFLINE
STATE=OFFLINE
does the database report the service ?
SYS@DB112> select name from all_services;
NAME
----------------------------------------------------------------
SYS$BACKGROUND
SYS$USERS
DB112
… not yet. lets start the service:
srvctl start service -d DB112 -s beer
… and check what oracle restart reports for the service now:
crsctl stat res ora.db112.beer.svc
NAME=ora.db112.beer.svc
TYPE=ora.service.type
TARGET=ONLINE
STATE=ONLINE on oracleplayground
seems to be online. does the database report the service now? :
SYS@DB112> select name from all_services;
NAME
----------------------------------------------------------------
SYS$BACKGROUND
SYS$USERS
DB112
BEER
yes. once the service is started the database reports the service in the appropriate views. to quickly check the attributes and state of the service:
srvctl config service -d DB112 -s beer -v
Service name: BEER
Service is enabled
Cardinality: SINGLETON
Disconnect: false
Service role: PRIMARY
Management policy: AUTOMATIC
DTP transaction: false
AQ HA notifications: false
Failover type: NONE
Failover method: NONE
TAF failover retries: 0
TAF failover delay: 0
Connection Load Balancing Goal: LONG
Runtime Load Balancing Goal: SERVICE_TIME
TAF policy specification: NONE
Edition:
thats all you need to do. a new service is created and the service is up and running. one more thing to consider: will the service be started automatically once the database is restarted? :
srvctl stop database -d DB112
srvctl start database -d DB112
crsctl stat res ora.db112.beer.svc
NAME=ora.db112.beer.svc
TYPE=ora.service.type
TARGET=ONLINE
STATE=ONLINE on oracleplayground
yes, it will.
for creating the second service i will use the dbms_service package.
the dbms_service way:
BEGIN
DBMS_SERVICE.CREATE_SERVICE (
service_name => 'MOREBEER'
, network_name => 'MOREBEER'
, goal => DBMS_SERVICE.GOAL_THROUGHPUT
, dtp => NULL
, aq_ha_notifications => NULL
, failover_method => NULL
, failover_type => NULL
, failover_retries => NULL
, failover_delay => NULL
, clb_goal => NULL
, edition => NULL
);
END;
/
in contrast to the srvctl method the database already knows about the service now:
select name from all_services;
NAME
----------------------------------------------------------------
SYS$BACKGROUND
SYS$USERS
DB112
BEER
MOREBEER
lets start the service:
BEGIN
dbms_service.start_service (
service_name => 'MOREBEER'
, instance_name => 'DB112'
);
END;
/
thats it. service up and running.
to make things a little easier for us oracle already registered the services with listener:
lsnrctl services listener_db112
LSNRCTL for Linux: Version 11.2.0.3.0 - Production on 22-MAY-2012 12:46:25
Copyright (c) 1991, 2011, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=LISTENER_DB112)))
Services Summary...
Service "BEER" has 1 instance(s).
Instance "DB112", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
Service "DB112" has 1 instance(s).
Instance "DB112", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
Service "MOREBEER" has 1 instance(s).
Instance "DB112", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
The command completed successfully
… and modified the services parameter:
show parameter service_names
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
service_names string BEER, MOREBEER
quickly check if the database starts up the second service if we bounce the instance:
srvctl stop database -d db112
srvctl start database -d db112
lsnrctl services listener_db112
LSNRCTL for Linux: Version 11.2.0.3.0 - Production on 22-MAY-2012 12:53:45
Copyright (c) 1991, 2011, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=LISTENER_DB112)))
Services Summary...
Service "BEER.fun" has 1 instance(s).
Instance "DB112", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
Service "DB112.fun" has 1 instance(s).
Instance "DB112", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
The command completed successfully
no. only the service which was created through srvctl is up and running. if you want services to startup automatically you created with the dbms_service package you’ll need to create triggers similar to this:
CREATE OR REPLACE TRIGGER MOREBEER_STARTUP
AFTER STARTUP ON DATABASE
BEGIN
dbms_service.start_service (
service_name => 'MOREBEER'
, instance_name => 'DB112'
);
END;
/
CREATE OR REPLACE TRIGGER MOREBEER_SHUTDOWN
BEFORE SHUTDOWN ON DATABASE
BEGIN
dbms_service.stop_service (
service_name => 'MOREBEER'
, instance_name => 'DB112'
);
END;
/
restart the database and check if it works:
srvctl stop database -d db112
srvctl start database -d db112
lsnrctl services listener_db112
LSNRCTL for Linux: Version 11.2.0.3.0 - Production on 22-MAY-2012 12:58:15
Copyright (c) 1991, 2011, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=LISTENER_DB112)))
Services Summary...
Service "BEER.fun" has 1 instance(s).
Instance "DB112", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
Service "DB112.fun" has 1 instance(s).
Instance "DB112", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
Service "MOREBEER.fun" has 1 instance(s).
Instance "DB112", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
The command completed successfully
works. both services will now survive a database restart. time to connect to the services…
as I will use sqlplus for the connections I will need two more entries in my tnsnames.ora:
BEER.fun =
(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS= (PROTOCOL = TCP)(Host = oracleplayground.fun)(Port = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = BEER.fun)
)
)
MOREBEER.fun =
(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS= (PROTOCOL = TCP)(Host = oracleplayground.fun)(Port = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = MOREBEER.fun)
)
)
… quickly check if I can reach the listener:
tnsping beer
TNS Ping Utility for Linux: Version 11.2.0.3.0 - Production on 22-MAY-2012 13:03:44
Copyright (c) 1997, 2011, Oracle. All rights reserved.
Used parameter files:
/opt/oracle/product/base/11.2.0.3/network/admin/sqlnet.ora
Used TNSNAMES adapter to resolve the alias
Attempting to contact (DESCRIPTION= (ADDRESS_LIST= (ADDRESS= (PROTOCOL = TCP)(Host = oracleplayground.fun)(Port = 1521))) (CONNECT_DATA = (SERVICE_NAME = BEER)))
OK (10 msec)
tnsping morebeer
TNS Ping Utility for Linux: Version 11.2.0.3.0 - Production on 22-MAY-2012 13:04:04
Copyright (c) 1997, 2011, Oracle. All rights reserved.
Used parameter files:
/opt/oracle/product/base/11.2.0.3/network/admin/sqlnet.ora
Used TNSNAMES adapter to resolve the alias
Attempting to contact (DESCRIPTION= (ADDRESS_LIST= (ADDRESS= (PROTOCOL = TCP)(Host = oracleplayground.fun)(Port = 1521))) (CONNECT_DATA = (SERVICE_NAME = MOREBEER)))
OK (10 msec)
fine. for the following I just did a seperate connection to each service and generated some load. once the connections are established you can use the service views to query data about your services:
ALL_SERVICES
V$SERVICEMETRIC
V$SERVICEMETRIC_HISTORY
V$SERVICES
V$SERVICE_EVENT
V$SERVICE_STATS
V$SERVICE_WAIT_CLASS
V$ACTIVE_SERVICES
if there are performance issues awr displays some performance data by service, too:
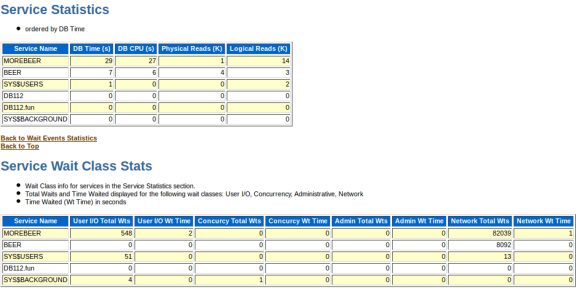 service stats in awr
service stats in awr
as well as the ash report:
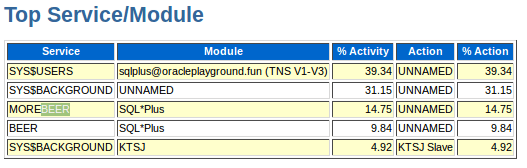 service stats in ash
service stats in ash
this is the foundation you may use when thinking about application consolidation into a single database. of course you should go further and integrate the services with the database resource manager to minimize impacts between the services or applications … and by the way: splitting a single application into services might be a good idea, too


 the virtual file system
the virtual file system directory listing
directory listing