
often there is the requierement to generate some test data. here are some examples for postgres.
generate_series
the generate_series function is one convenient way for generating data, e.g:
generate increasing integer values:
edb=# select generate_series(1,10);
generate_series
-----------------
1
2
3
4
5
6
7
8
9
10
(10 rows)
or:
edb=# select generate_series(-10,-1);
generate_series
-----------------
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
generate increasing integer values with steps:
edb=# select generate_series(0,50,5);
generate_series
-----------------
0
5
10
15
20
25
30
35
40
45
50
(11 rows)
generate decreasing integer values:
edb=# select generate_series(10,0,-1);
generate_series
-----------------
10
9
8
7
6
5
4
3
2
1
0
or:
edb=# select generate_series(10,0,-5);
generate_series
-----------------
10
5
0
generating date values:
edb=# select * from generate_series( '2015-01-01 00:00'::timestamp
, '2015-01-01 08:00'::timestamp
, '1 hour');
generate_series
--------------------
01-JAN-15 00:00:00
01-JAN-15 01:00:00
01-JAN-15 02:00:00
01-JAN-15 03:00:00
01-JAN-15 04:00:00
01-JAN-15 05:00:00
01-JAN-15 06:00:00
01-JAN-15 07:00:00
01-JAN-15 08:00:00
(9 rows)
generate_series and random()
combining generate_series and random() is another way:
edb=# select generate_series(10,0,-1) order by random();
generate_series
-----------------
0
9
3
10
6
5
2
8
7
1
4
(11 rows)
or:
select * from generate_series( '2015-01-01 00:00'::timestamp
, '2015-01-01 08:00'::timestamp
, '1 hour') order by random();
generate_series
--------------------
01-JAN-15 04:00:00
01-JAN-15 08:00:00
01-JAN-15 05:00:00
01-JAN-15 02:00:00
01-JAN-15 07:00:00
01-JAN-15 03:00:00
01-JAN-15 06:00:00
01-JAN-15 01:00:00
01-JAN-15 00:00:00
(9 rows)
generate_series and random() and md5()
adding md5() to the picture:
edb=# select generate_series(1,5) as a, md5(random()::text); a | md5 ---+---------------------------------- 1 | 5eb731819cf0dbed770ae8d5f11a27ef 2 | 995360f0745610e9bc9d73abd954196c 3 | 1461efd0dc899a8eae612439585935b0 4 | e4bd67cd9f9bb0034a21dffabfe97509 5 | 8b7c099d4064be2134ebc6ad11b3ce47
generate_series and random() and md5() and common table expressions
adding common table expressions to the picture:
with testdata1 as
( select generate_series(1,5) as a , md5(random()::text) as b ),
testdata2 as
( select generate_series(10,0,-2) as c order by random() ),
testdata3 as
( select * from generate_series( '2015-01-01 00:00'::timestamp
, '2015-01-01 08:00'::timestamp
, '1 hour') as d )
select case when testdata1.a = 4 then 1 else 0 end a
, testdata1.b
, testdata2.c
, testdata3.d
from testdata1
, testdata2
, testdata3
order by random()
limit 10;
a | b | c | d
---+----------------------------------+----+--------------------
0 | 542d402aa1d5bc3945b692cdf8bde4bc | 10 | 01-JAN-15 05:00:00
0 | 58c1b1e0ddc072e9e83e4ca31064a4ef | 4 | 01-JAN-15 06:00:00
0 | 8d917cf5c06539574fcc79089ff0b66d | 4 | 01-JAN-15 07:00:00
0 | 8d917cf5c06539574fcc79089ff0b66d | 2 | 01-JAN-15 08:00:00
0 | 58c1b1e0ddc072e9e83e4ca31064a4ef | 6 | 01-JAN-15 07:00:00
0 | 58c1b1e0ddc072e9e83e4ca31064a4ef | 0 | 01-JAN-15 01:00:00
0 | 542d402aa1d5bc3945b692cdf8bde4bc | 2 | 01-JAN-15 08:00:00
0 | 58c1b1e0ddc072e9e83e4ca31064a4ef | 8 | 01-JAN-15 07:00:00
0 | f1d9650423b432f75a50ae38591b1508 | 2 | 01-JAN-15 01:00:00
1 | 687b977261e44825b266f461e7547b08 | 6 | 01-JAN-15 01:00:00

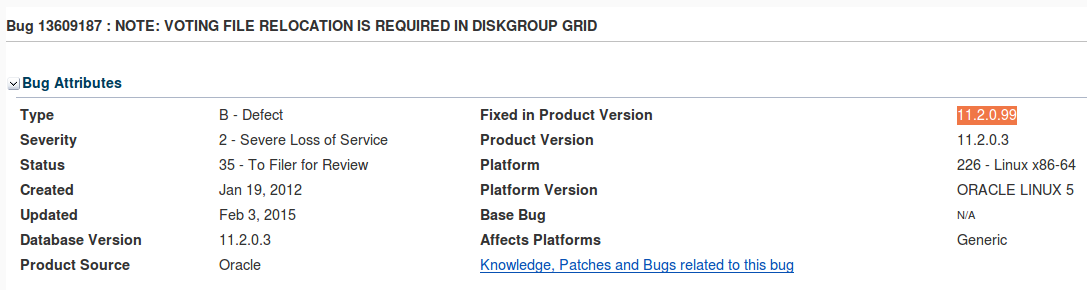 11.2.0.99
11.2.0.99