when it comes to the management of processes and data structures there is one essential concept: double linked lists
you can think of this concept as n lists ( memory structures ) linked together each containing pointers to the next and to the previous list:
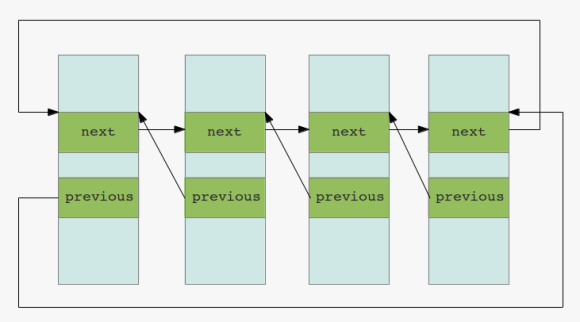 double linked lists
double linked lists
from the perspective of the linux kernel this lists help, for example, in tracking all the processes in the system. if it comes to the oracle database there is the same concept. all the caches and pools are based on double linked lists.
one place where you can see that oracle uses the same concept is the buffer headers. although you can not see it in v$bh oracle exposes the information in the underlying x$bh:
SQL> select NXT_REPL,PRV_REPL from x$bh where rownum < 5;
NXT_REPL PRV_REPL
-------- --------
247E550C 247E535C
23BE334C 23BE319C
23BF38DC 23BF372C
22FE694C 22FE679C
these are some pointers to the next and previous lists mentioned above. you can even check the relations:
SQL> select NXT_REPL,PRV_REPL from x$bh where NXT_REPL = '23BF38DC' or PRV_REPL = '23BF38DC';
NXT_REPL PRV_REPL
-------- --------
23BF38DC 23BF372C
23BF3A8C 23BF38DC
for managing these lists there must be some atomic ( notice the vocabulary, it’s the same as the A in ACID ) operations implemented:
- initialize the list
- inserting and deleting elements
- walking through the list for finding an element
- checking for empty elements in the list
- …
the list of processes in linux is called the process list. this list links together all the processes in the system, more exactly: it links together all the process descriptors. if the kernel wants to know which processes are ready to run, it scans the list for all processes in state TASK_RUNNING. there are several others states a process can be in:
- TASK_RUNNING: the process waits to be executed or currently is executing
- TASK_INTERRUPTIBLE: the process sleeps until some event occurs
- TASK_UNINTERRUPTIBLE: the process sleeps and will not wake up on a signal
- TASK_STOPPED: the process is stopped
- TASK_TRACED: the process is being traced
when one process creates one or more other processes there are one or more parent/child relationships. this relationships are present in the process descriptors. the init process ( which is pid 1 ) is the master ( or the anchor ) of all other processes. all this relations are managed by linked lists.
for the kernel to quickly find an entry in one of the lists another concept is introduced: hashing. hashing data is an efficient way to locate an element in a list. for example the number 85 might hash to the 10th entry of a list ( so after hashing the kernel can jump directly to this entry instead of scanning the whole list for the value in question ). this is another link to the oracle database as oracle is excessively using hashing, too ( for example to quickly locate sql-statements in the shared pool oracle hashes the text of the statement ).
you probably heard of locks in the oracle world. next link between the os and the database. when elements of lists are modified there is a need to protect them from concurrent access. imagine what happens if two ( or more ) processes try to modify the same data at the same time. this is where locks come into play: locks provide a mechanism for synchronization. in the linux kernels wait queues, for example, there are exclusive processes and nonexclusive processes. the latter are always woken up by the kernel if some specific events occur while the exclusive processes are woken up selectively ( for example if they want to access a resource only one processes can be granted to at a time ). again, you see same vocabulary here than in the oracle database world: there are exclusive locks, shared locks, etc.
by the way: keeping the duration of the locks as short as possible without risking data inconsistency is one key to performance. because if there are locks there is very good chance that others have to wait until the locks disappear ( and waiting is wasted time in terms of performance ). this is why mutexes appeared in the oracle database: they provide a faster way of protecting data than the traditional latches ( which are a kind of lock in the oracle database ).
conclusion: if you understand how the operating system handles resources it is not a big deal to understand some basic workings of the database. much is about double linked lists and protecting data. even the vocabulary is the same very often. you see the same terms over and over again ( queues, locks, spins, lists, waits …. ).
if you want to go into more detail on how oracle handles lists, check out james morle’s book scalingoracle8i which is available for download now. don’t care about the 8i, the basics are still the same.
happy listing …


