
the first optimizer post tried to introduce the very basic knowledge you need for understanding how the optimizer decides on how to get the data users are requesting.
the key points discovered were:
- full table scans are not always bad, as the database can read multiple block at a time
- indexes do not always help, as index access is always sequential and always block by block
- statistics are the basics which help the optimizer with its decisions
- statistics might be wrong
this post will discuss the question: how does the optimizer decide if an index gets used or not ?
this time, image the following scenario: in your city there is a very, very, very long road with 10’000 houses on the right side, and because there is no sun at the left side there are no houses ( or for what ever reason you like :) ). each house is located next to the other and is identified by its house number. in addition, as lots of people love to do smalltalk by phone, there is a phone number for each house. in contrast to the phone numbers which are assigned random, the house numbers start by one for the first house and increase to ten thousand for the last one. house by house.
the table representing this scenario could look like this one:
DROP TABLE T1;
CREATE TABLE T1 ( HOUSENUMBER NUMBER
, PHONENUMBER NUMBER
) TABLESPACE USERS;
as the scenario assumes one phone number per house the content could look as follows:
BEGIN
FOR
i IN 1..10000
LOOP
INSERT INTO T1 ( HOUSENUMBER, PHONENUMBER )
VALUES ( i, ROUND ( dbms_random.value(1,10000), 0 ) );
END LOOP;
COMMIT;
END;
/
exec dbms_stats.gather_table_stats ( USER, 'T1', NULL, 100 );
lets quickly check how our houses are organized:
SELECT num_rows houses
, blocks
FROM user_tables
WHERE table_name = 'T1';
HOUSES BLOCKS
---------- ----------
10000 20
this tells that the database grouped our ten thousand houses in twenty blocks. well, this is a common way to group houses in the US, but not in Europe. anyway, if we try to put this on a picture it looks similar to this one ( if you have problems reading the numbers scroll down to the end of this post to find the URLs ):
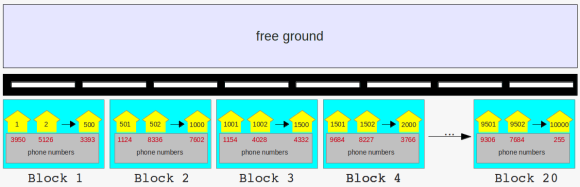 long street with tiny houses, grouped into blocks
long street with tiny houses, grouped into blocks
as the frustrated teacher in the first post discovered you will need to walk down all the road no matter if you search for a phone- or a house number nor how much of each. this is the only solution right now. even the search for exactly one phone number will require you to take a real long walk:
SET AUTOTRACE ON;
SELECT phonenumber
FROM t1
WHERE housenumber = 1;
Execution Plan
----------------------------------------------------------
Plan hash value: 3617692013
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 | 7 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T1 | 1 | 8 | 7 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("HOUSENUMBER"=1)
but the teacher learned that creating indexes sometimes helps to reduce the amount of work and to provide the answer in a much faster way:
CREATE INDEX I_HOUSENUMBER ON T1 ( HOUSENUMBER );
lets see if this helps:
SET AUTOTRACE ON;
SELECT phonenumber
FROM t1
WHERE housenumber = 1;
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 8 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | I_HOUSENUMBER | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("HOUSENUMBER"=1)
same for the phone number:
CREATE INDEX I_PHONENUMBER ON T1 ( PHONENUMBER );
SET AUTOTRACE ON;
SELECT housenumber
FROM t1
WHERE phonenumber = 5126;
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 16 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 2 | 16 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | I_PHONENUMBER | 2 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("PHONENUMBER"=5126)
helps, too. both indexes seem to be useful for the queries above. what happens if we go further and increase the range:
SET AUTOTRACE ON;
SELECT phonenumber
FROM t1
WHERE housenumber < 100;
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 99 | 792 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 99 | 792 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | I_HOUSENUMBER | 99 | | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("HOUSENUMBER"<100)
still ok for the house number. what’s with the phone number? :
SET AUTOTRACE ON;
SELECT housenumber
FROM t1
WHERE phonenumber < 100;
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 99 | 792 | 7 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T1 | 99 | 792 | 7 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("PHONENUMBER"<100)
damn. although there is an index on the phone number column and we are not querying that much data the index is not used, while the index for the house number gets used. and both queries return a similar amount of data ( it is quite possible that the dbms_random function used to generate the numbers produces more results for one number and no result for a another number. in this way the use case is not totally correct as the same phone number may be assigned to more than one house but this is not very important here ).
back to the question: how can this be? for answering the questions lets expand the scenario: the sun comes back to the other side of the road and our first index ( I_HOUSENUMBERS ) decided that the left side of the road is a really nice place to life:
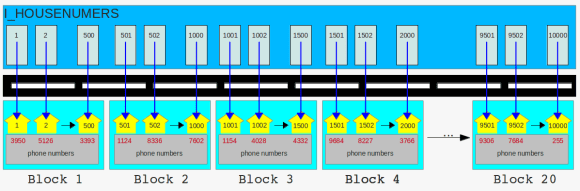 the houses got new neighbors
the houses got new neighbors
in the morning the postman wants deliver some letters to house numbers 501 – 1000. because the postman does not want to walk the whole road she goes directly to the index and searches for house number 500. happily for delivering the letters to the house with house number 501 the postman just needs to go directly to the block on the opposite of the street. the procedure is the same for the house numbers 502 to 1000. very short distances to go and no need to walk the whole road. all houses are located in the same block.
as people are telling that the environment around our street is one of the best places to life in town, the mayor decided to build a new road to make more people come to town:
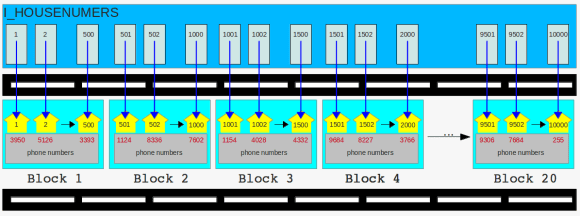 the new road is ready
the new road is ready
it is not taking too much time: once the new road is ready our second index ( I_PHONENUMBERS ) took the chance for a new home and settled down by the brand new road:
 more neighbors
more neighbors
one sunny day the phone company which assigned the phone numbers to the houses sends an assistant to check if the phone numbers 4200 – 4300 are still correctly assigned. the assistant is lazy, too, so she directly goes to the phone number index. she searches for entry 4200, follows the pointer and walks down the road to block 3 where she finds the corresponding house. once she noticed that the phone number is still assigned correctly she goes all the way back to the index, picks up the next pointer for phone number 4201 and ends up at block 19 where she finds the house belonging to the phone number. once verified, she goes again back to the index, sees the pointer for phone number 4203 and walks down the road to block 2. and back to index, next pointer, different block. and on and on and on. in the worst case she has to visit a different block for each pointer and maybe visit the same block twice or more. after hours of walking she can finally return to the office and deliver the results. for the next time she promised herself: I will walk down the whole road from the beginning to the end and not visit the index. that will save me a lot of steps.
it is the same with the optimizer. each index has an attribute called the clustering_factor:
SELECT index_name
, num_rows
, clustering_factor
FROM user_indexes
WHERE index_name IN ( 'I_HOUSENUMBER','I_PHONENUMBER' )
ORDER BY 1;
INDEX_NAME NUM_ROWS CLUSTERING_FACTOR
------------------------------ ---------- -----------------
I_HOUSENUMBER 10000 18
I_PHONENUMBER 10000 9411
the clustering_factor describes how well the table is sorted in relation to the index. the house number index has a clustering_factor of 18, which is close to number of blocks of the table:
SELECT num_rows
, blocks
FROM user_tables
WHERE table_name = 'T1';
NUM_ROWS BLOCKS
---------- ----------
10000 20
what does this tell the optimizer? this means how many times the database will need to read a different block of the table for finding the rows pointed to by the index. for example:
- we know the first 500 rows of the table are all stored in the first block
- if someone now requests the phone numbers of the first 500 houses the database will need to read a single block of the table where all the index pointers point to
- in contrast, if someone requests the house number for the first 500 phone numbers the database will need to read several blocks of the table as the pointers might all point to different blocks of the table
the clustering_factor 9411 of the phone number index tells the optimizer that is likely that the database needs to access a different block for every consecutive pointer in the index. you may have noticed that the clustering_factor of 9411 is close to the number of rows in the table. this means, in regards to I/O: might be much to expensive if several rows must be retrieved. although the clustering_factor is not the only statistic the optimizer uses to make its decisions, it is an important one. good to know for the mayor if he wants to build another street …
URLs for the pictures in original size:
long street with tiny houses, grouped into blocks
the houses got new neighbors
the new road is ready
more neighbors

