
head over to the blog of dbi services to read the full article:
Archives For November 30, 1999
The second posts on the topic are now online:
Oracle post done by my colleague Franck Pachot: Variations on 1M rows insert(2): commit write
PostgreSQL post done be me: Variations on 1M rows insert(2): commit write – PostgreSQL
Have fun with the test cases …

Again, head over to the dbi services blog:
Oracle post done by my colleague Franck Pachot: Variations on 1M rows insert (1): bulk insert
PostgreSQL post done be me: Variations on 1M rows insert (1): bulk insert – PostgreSQL
Have fun with the test cases …
if you do a solaris 10u11 core/minimal installation and after that add all packages listed in the documentation the oracle database 12.1.0.2 software installation will fail with:
WARNING: Verification of target environment returned with errors. WARNING: [WARNING] [INS-13001] Environment does not meet minimum requirements. CAUSE: Minimum requirements were not met for this environment ACTION: Either check the logs for more information or check the supported configurations for this product.. Refer associated stacktrace #oracle.install.commons.util.exception.DefaultErrorAdvisor:339 INFO: Advice is CONTINUE WARNING: Advised to ignore target environment verification errors. INFO: Verifying setup for installer validations INFO: Overall status of CVU API call:OPERATION_FAILED SEVERE: [FATAL] [INS-30131] Initial setup required for the execution of installer validations failed. CAUSE: Failed to access the temporary location. ACTION: Ensure that the current user has required permissions to access the temporary location.
this is a bit misleading. the real cause of this (at least in my case) are missing packages:
SUNWpool SUNWpoolr
once these are installed the installation will succeed.
this continues the previous post on the oracle compatibility layer available in ppas. while this previous post introduced some parameters which control the behaviour for dates, strings, object names and transaction isolation this post focusses on some features/helpers that are available in oracle but are not (by default) in plain postgresql. ppas adds these whith the oracle compatibility layer.
dual
as in oracle there is a dual table in ppas:
edb=# select 1+1 from dual;
?column?
----------
2
(1 row)
edb=# \d dual;
Table "sys.dual"
Column | Type | Modifiers
--------+----------------------+-----------
dummy | character varying(1) |
synonyms
there are no synonyms available in community postgres. there are in ppas:
edb=# create table t1 ( a int );
CREATE TABLE
edb=# insert into t1 values (1);
INSERT 0 1
edb=# create synonym s1 for t1;
CREATE SYNONYM
edb=# create public synonym ps1 for t1;
CREATE SYNONYM
edb=# select count(*) from s1;
count
-------
1
(1 row)
edb=# select count(*) from ps1;
count
-------
1
(1 row)
for describing synonyms “describe” must be used, the “\d” switch will not work:
edb=# desc ps1
List of synonyms
Schema | Synonym | Referenced Schema | Referenced Object | Link | Owner
--------+---------+-------------------+-------------------+------+--------------
public | ps1 | enterprisedb | t1 | | enterprisedb
(1 row)
Table "enterprisedb.t1"
Column | Type | Modifiers
--------+---------+-----------
a | integer |
edb=# \d ps1
Did not find any relation named "ps1".
more details here.
rownum
the pseudo column rownum is available in ppas:
edb=# create table t1 ( a int ); CREATE TABLE edb=# insert into t1 values ( generate_series ( 1, 50 ) ); INSERT 0 50 edb=# select a, rownum from t1 where rownum < 5; a | rownum ---+-------- 1 | 1 2 | 2 3 | 3 4 | 4 (4 rows)
more details here.
packages
community postgresql does not know the concept of packages. ppas implements this:
edb=# create package p1
edb-# as
edb$# procedure pc1;
edb$# end p1;
CREATE PACKAGE
edb=# create package body p1
edb-# as
edb$# procedure pc1
edb$# as
edb$# begin
edb$# dbms_output.put_line('a');
edb$# end pc1;
edb$# begin
edb$# null;
edb$# end p1;
CREATE PACKAGE BODY
edb=# exec p1.pc1;
a
EDB-SPL Procedure successfully completed
more details here.
build-in packages
ppas comes with a set of build-in packages:
edb=# select distinct name from dba_source where type = 'PACKAGE' order by 1;
name
----------------
DBMS_ALERT
DBMS_CRYPTO
DBMS_JOB
DBMS_LOB
DBMS_LOCK
DBMS_MVIEW
DBMS_OUTPUT
DBMS_PIPE
DBMS_PROFILER
DBMS_RANDOM
DBMS_RLS
DBMS_SCHEDULER
DBMS_SQL
DBMS_UTILITY
UTL_ENCODE
UTL_FILE
UTL_HTTP
UTL_MAIL
UTL_SMTP
UTL_TCP
UTL_URL
more details here.
edbplus
if someone prefers to work in a splplus like environment there is edbplus:
pwd /opt/PostgresPlus/9.4AS -bash-4.2$ edbplus/edbplus.sh enterprisedb/admin123 Connected to EnterpriseDB 9.4.1.3 (localhost:5444/edb) AS enterprisedb EDB*Plus: Release 9.4 (Build 33.0.0) Copyright (c) 2008-2015, EnterpriseDB Corporation. All rights reserved. SQL> help index Type 'HELP [topic]' for command line help. @ ACCEPT APPEND CHANGE CLEAR COLUMN CONNECT DEFINE DEL DESCRIBE DISCONNECT EDBPLUS EDIT EXIT GET HELP HOST INDEX INPUT LIST PASSWORD PAUSE PRINT PROMPT QUIT REMARK SAVE SET SHOW SPOOL START UNDEFINE VARIABLE
head over to the documentation to check what is already supported.
Dynamic Runtime Instrumentation Tools Architecture (DRITA)
drita is a kind of perfstat which can be used to analyse performance issues. the usage is straight forward:
as a first step timed_statistics need to be enabled:
edb=# show timed_statistics; timed_statistics ------------------ off (1 row) edb=# alter system set timed_statistics=true; ALTER SYSTEM edb=# select pg_reload_conf(); pg_reload_conf ---------------- t (1 row) edb=# show timed_statistics; timed_statistics ------------------ on (1 row)
after that lets create a snapshot:
edb=# SELECT * FROM edbsnap();
edbsnap
----------------------
Statement processed.
(1 row)
… and generate some load on the system:
edb=# create table t1 ( a int, b int );
CREATE TABLE
edb=# create table t2 ( a int, b int );
CREATE TABLE
edb=# insert into t1 values ( generate_series ( 1,10000)
, generate_series ( 1,10000) );
INSERT 0 10000
edb=# insert into t2 values ( generate_series ( 1,10000)
, generate_series ( 1,10000) );
INSERT 0 10000
edb=# select count(*) from t1, t2;
count
-----------
100000000
(1 row)
create another snapshot:
edb=# SELECT * FROM edbsnap();
edbsnap
----------------------
Statement processed.
(1 row)
as we need the snapshot ids to generate a report lets check what we have available:
edb=# select * from get_snaps();
get_snaps
-----------------------------
1 24-FEB-15 16:21:55.420802
2 24-FEB-15 16:25:16.429357
(2 rows)
now we can generate a report, e.g. the report for system wait information:
edb=# select * from sys_rpt(1,2,10);
sys_rpt
-----------------------------------------------------------------------------
WAIT NAME COUNT WAIT TIME % WAIT
---------------------------------------------------------------------------
autovacuum lock acquire 18 0.040010 73.84
query plan 2 0.011015 20.33
db file read 6 0.003124 5.77
xid gen lock acquire 3 0.000021 0.04
sinval lock acquire 7 0.000006 0.01
buffer free list lock acquire 9 0.000005 0.01
freespace lock acquire 0 0.000001 0.00
wal buffer mapping lock acquire 0 0.000000 0.00
multi xact gen lock acquire 3 0.000000 0.00
wal flush 0 0.000000 0.00
(12 rows)
there are many other reports which can be generated, inluding:
- sess_rpt() for session wait information
- sessid_rpt() for session ID information for a specified backend
- sesshist_rpt() for session wait information for a specified backend
- edbreport() for data from the other reporting functions, plus additional system information
- …
more details here.
oracle like catalog views
various oracle like catalog views (all_*, dba_*, user_*) are available in ppas:
edb=# select schemaname,viewname
from pg_views
where viewname like 'dba%' order by 1,2 limit 5;
schemaname | viewname
------------+------------------
sys | dba_all_tables
sys | dba_cons_columns
sys | dba_constraints
sys | dba_db_links
sys | dba_ind_columns
(5 rows)
more details here.
summary
enterprise db did a great job making life easier for oracle dbas wanting to learn postgresql. in addition the oracle compatibility layer lowers the burdens of migrating applications from oracle to postgres significantly. you almost can start immediately working on a postgresql database by using your existing oracle skills.
the above is only a sub-set of what the oracle compatibility layer provides. for a complete overview check the official documentation.
edbs ppas comes with an oracle compatibility layer. in this and some future posts I’ll take a look at what this layer is about and what you can do with it.
there are four parameters which control the behaviour of the oracle compatibility layer:
- edb_redwood_date
- edb_redwood_raw_names
- edb_redwood_strings
- edb_stmt_level_tx
lets check the catalog for these parameters and see if we can change them on the fly or if we need to restart the database server:
select name,setting,context
from pg_settings
where name in ('edb_redwood_date'
,'edb_redwood_raw_names'
,'edb_redwood_strings'
,'edb_stmt_level_tx');
name | setting | context
-----------------------+---------+---------
edb_redwood_date | on | user
edb_redwood_raw_names | off | user
edb_redwood_strings | on | user
edb_stmt_level_tx | off | user
fine, all have the context “user” which means we can change them without restarting the server (btw: the above settings are the default if ppas is installed in oracle compatibility mode).
what is edb_redwood_date about?
in postgres, if you specify a column as date there is no time information. setting this parameter to “on” tells the server to use a timestamp instead of pure date data type whenever date is specified for a column. in oracle a column of type date includes the time component, too.
lets switch it to off for now:
edb=# alter system set edb_redwood_date=off;
ALTER SYSTEM
edb=# select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
edb=# select name,setting,context from pg_settings where name = 'edb_redwood_date';
name | setting | context
------------------+---------+---------
edb_redwood_date | off | user
(1 row)
and now lets create a simple table with a date column and insert one row:
edb=# create table t1 ( a date );
CREATE TABLE
edb=# \d t1
Table "enterprisedb.t1"
Column | Type | Modifiers
--------+------+-----------
a | date |
edb=# insert into t1 values (date '2014-01-01');
INSERT 0 1
edb=# select * from t1;
a
-----------
01-JAN-14
(1 row)
no time component available. now switch edb_redwood_date to “on”:
edb=# alter system set edb_redwood_date=on;
ALTER SYSTEM
edb=# select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
edb=# select name,setting,context from pg_settings where name = 'edb_redwood_date';
name | setting | context
------------------+---------+---------
edb_redwood_date | on | user
(1 row)
… and create another table with type date for the column and do the same insert:
edb=# create table t2 ( a date );
CREATE TABLE
edb=# insert into t2 values ( date '2014-01-01');
INSERT 0 1
edb=# select * from t2;
a
--------------------
01-JAN-14 00:00:00
(1 row)
here we go. the time component is now included. but how is this possible? the server created the column with type “timestamp (0)” on the fly:
edb=# \d t2
Table "enterprisedb.t2"
Column | Type | Modifiers
--------+-----------------------------+-----------
a | timestamp without time zone |
what is edb_redwood_raw_names about?
when oracle compatibilty mode is used various oracle catalog views are accessible in ppas, e.g;
edb=# select viewname from pg_views where viewname like 'dba%' limit 5;
viewname
-----------------
dba_tables
dba_users
dba_constraints
dba_all_tables
dba_triggers
(5 rows)
now lets create two tables while edb_redwood_raw_names is set to its default (false/off):
edb=# create table TEST1 (A int); CREATE TABLE edb=# create table test2 (a int); CREATE TABLE
both of these tables are displayed in upper case when looking at the oracle catalog views:
edb=# select table_name from dba_tables where table_name in ('TEST1','TEST2');
table_name
------------
TEST1
TEST2
(2 rows)
setting edb_redwood_raw_names to true/on changes this behaviour:
edb=# set edb_redwood_raw_names to on;
SET
edb=# show edb_redwood_raw_names;
edb_redwood_raw_names
-----------------------
on
(1 row)
edb=# create table TEST3 (A int);
CREATE TABLE
edb=# create table test4 (a int);
CREATE TABLE
edb=# select table_name from dba_tables where table_name in ('TEST3','TEST4');
table_name
------------
(0 rows)
edb=# select table_name from dba_tables where table_name in ('test3','test4');
table_name
------------
test3
test4
(2 rows)
what is edb_redwood_strings about?
edb_redwood_strings controls concatenation of strings. in plain postgres, if a string is concatenated with null the result is null:
edb=# show edb_redwood_strings; edb_redwood_strings --------------------- on (1 row) edb=# set edb_redwood_strings to off; SET edb=# show edb_redwood_strings; edb_redwood_strings --------------------- off (1 row) edb=# select 'aaaa'||null; ?column? ---------- (1 row)
in oracle the behaviour is the other way around. if a string is concatenated with null the result is the original string:
edb=# set edb_redwood_strings to on; SET edb=# show edb_redwood_strings; edb_redwood_strings --------------------- on (1 row) edb=# select 'aaaa'||null; ?column? ---------- aaaa (1 row)
what is edb_stmt_level_tx about?
this is all about “statement level transaction isolation”, which is the default behaviour in oracle. lets set up a little test case to demonstrate this:
edb=# create table t1 ( a int, b varchar(3) );
CREATE TABLE
edb=# alter table t1 add constraint chk_b check ( b in ('aaa','bbb'));
ALTER TABLE
edb=# create table t2 ( c int, d date );
CREATE TABLE
edb=# alter table t2 add constraint chk_c check ( c in (1,2,3));
ALTER TABLE
the default setting for edb_stmt_level_tx is off:
edb=# show edb_stmt_level_tx; edb_stmt_level_tx ------------------- off (1 row)
lets insert some rows in the tables and let the last insert fail (autocommit needs to be off as each statement commits automatically otherwise):
edb=# set autocommit off; edb=# show autocommit; autocommit OFF edb=# insert into t1 (a,b) values (1,'aaa'); INSERT 0 1 edb=# insert into t1 (a,b) values (2,'aaa'); INSERT 0 1 edb=# insert into t2 (c,d) values (1,sysdate); INSERT 0 1 edb=# insert into t2 (c,d) values (5,sysdate); ERROR: new row for relation "t2" violates check constraint "chk_c" DETAIL: Failing row contains (5, 24-FEB-15 10:52:29).
if we now do a commit, which rows are there?
edb=# commit; ROLLBACK edb=# select * from t1; a | b ---+--- (0 rows) edb=# select * from t2; c | d ---+--- (0 rows)
all gone (notice the ROLLBACK after the commit statement). lets witch edb_stmt_level_tx to on and repeat the test:
edb=# set edb_stmt_level_tx to on; SET edb=# show edb_stmt_level_tx; edb_stmt_level_tx ------------------- on (1 row) edb=# show autocommit; autocommit OFF edb=# insert into t1 (a,b) values (1,'aaa'); INSERT 0 1 edb=# insert into t1 (a,b) values (2,'aaa'); INSERT 0 1 edb=# insert into t2 (c,d) values (1,sysdate); INSERT 0 1 edb=# insert into t2 (c,d) values (5,sysdate); ERROR: new row for relation "t2" violates check constraint "chk_c" DETAIL: Failing row contains (5, 24-FEB-15 10:55:52). edb=# commit; COMMIT edb=# select * from t1; a | b ---+----- 1 | aaa 2 | aaa (2 rows) edb=# select * from t2; c | d ---+-------------------- 1 | 24-FEB-15 10:55:49 (1 row)
now all the rows are there except for the failing one. this is what edb_stmt_level_tx is about. by default postgresql rolls back everything since the start of the transaction. when switching edb_stmt_level_tx to on only the failing statement is rolled back. in addition, if edb_stmt_level_tx is set to off you can not continue the transaction until either commit or rollback is issued:
edb=# set edb_stmt_level_tx to off; SET edb=# insert into t1 (a,b) values (1,'aaa'); INSERT 0 1 edb=# insert into t1 (a,b) values (2,'aaa'); INSERT 0 1 edb=# insert into t2 (c,d) values (1,sysdate); INSERT 0 1 edb=# insert into t2 (c,d) values (5,sysdate); ERROR: new row for relation "t2" violates check constraint "chk_c" DETAIL: Failing row contains (5, 24-FEB-15 11:06:52). edb=# insert into t2 (c,d) values (2,sysdate); ERROR: current transaction is aborted, commands ignored until end of transaction block
this is merely a documenation post for myself as I always forgot the steps to get this working. as postgres plus advanced server 9.4 was released some days ago we wanted to do another poc for an oracle migration. using edbmtk was clearly the preferred way to do this as it automates most of the tasks. but how did we need to set this up the last time?
as a first step one needs to download the oracle jdbc driver for the java version available on the postgres server.
example:
ojdbc6.jar – for use with java 6
ojdbc7.jar – for use with java 7
put one of these under:
ls -la /etc/alternatives/jre/lib/ext/ total 5264 drwxr-xr-x. 2 root root 4096 Feb 12 12:54 . drwxr-xr-x. 11 root root 4096 Jan 26 18:26 .. -rw-r--r--. 1 root root 10075 Jan 9 02:39 dnsns.jar -rw-r--r--. 1 root root 452904 Jan 9 02:48 gnome-java-bridge.jar -rw-r--r--. 1 root root 558461 Jan 9 02:40 localedata.jar -rw-r--r--. 1 root root 427 Jan 9 02:45 meta-index -rw-r--r--. 1 root root 3698857 Feb 12 12:54 ojdbc7.jar -rw-r--r--. 1 root root 69699 Jan 9 02:46 pulse-java.jar -rw-r--r--. 1 root root 225679 Jan 9 02:41 sunjce_provider.jar -rw-r--r--. 1 root root 259918 Jan 9 02:39 sunpkcs11.jar -rw-r--r--. 1 root root 78194 Jan 9 02:42 zipfs.jar
the next step is to configure the toolkit.properties file:
cat /opt/PostgresPlus/edbmtk/etc/toolkit.properties SRC_DB_URL=jdbc:oracle:thin:@[ORACLE_SERVER]:[LISTENER_PORT]:[DATABASE] SRC_DB_USER=system SRC_DB_PASSWORD=manager TARGET_DB_URL=jdbc:edb://localhost:5432/[POSTGRES_DATABASE] TARGET_DB_USER=postgres TARGET_DB_PASSWORD=postgres
… and then kickoff the migration:
cd /opt/PostgresPlus/edbmtk/bin ./runMTK.sh -fastCopy -logBadSQL -fetchSize 10000 -loaderCount 6 -dropSchema true -useOraCase ORACLE_SCHEMA1,ORACLE_SCHEMA2,...
pretty easy. wait for edbmtk to finish and start fixing the objects that are invalid :)
btw: for migrations to pure community postgres take a look at ora2pg
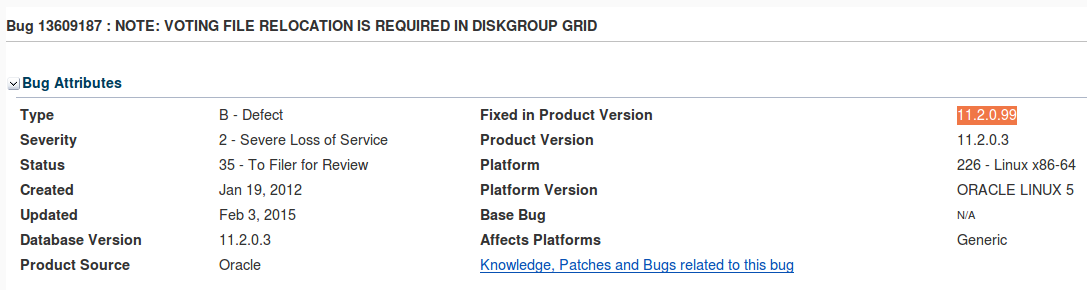 11.2.0.99
11.2.0.99some days ago we tried to remove a trusted certificate from an oracle wallet and this throwed “improperly specified input name”.
test-case:
Download the certificate from this website
create the wallet:
orapki wallet create -wallet . -pwd "Oracle1"
add the certificate to the wallet:
orapki wallet add -wallet . -cert a.pem -trusted_cert -pwd "Welcome1"
then try to remove it:
orapki wallet remove -wallet . -dn 'CN=www.cenduitsolutions.com,OU=Cenduit LLC,O=Cenduit LLC,L=Durham,ST=North Carolina,C=US,2.5.4.17=27703,STREET=4825 Creekstone Drive,STREET=Suite 400,SERIAL_NUM=4312751,1.3.6.1.4.1.311.60.2.1.2=Delaware,1.3.6.1.4.1.311.60.2.1.3=US,2.5.4.15=Private Organization' -trusted_cert -pwd "Welcome1" Oracle PKI Tool : Version 12.1.0.2 Copyright (c) 2004, 2014, Oracle and/or its affiliates. All rights reserved. improperly specified input name: CN=www.cenduitsolutions.com,OU=Cenduit LLC,O=Cenduit LLC,L=Durham,ST=North Carolina,C=US,2.5.4.17=27703,STREET=4825 Creekstone Drive,STREET=Suite 400,SERIAL_NUM=4312751,1.3.6.1.4.1.311.60.2.1.2=Delaware,1.3.6.1.4.1.311.60.2.1.3=US,2.5.4.15=Private Organization
turned out that this is because of oracle bug (13773007) which seems to be there since 11gR1 although the error message is slightly different. only certificates for which “the DN includes a serial number attribute” seem to be affected.
the workaround is to do it this way:
orapki wallet remove -wallet . -alias 'CN=www.cenduitsolutions.com' -trusted_cert -pwd "Welcome1"Oracle PKI Tool : Version 12.1.0.2 Copyright (c) 2004, 2014, Oracle and/or its affiliates. All rights reserved.
surprisingly the “-alias” switch seems not to be documented or least is not listed in the orapki help output.
lets say you have a diskgroup called “dummy”:
SYS@+ASM> select GROUP_NUMBER,NAME,STATE from v$asm_diskgroup where name = 'DUMMY'; GROUP_NUMBER NAME STATE ------------ ------------------------------ ----------- 3 DUMMY MOUNTED
currently the diskgroup contains once device:
SYS@+ASM> select name,path,header_status from v$asm_disk where group_number = 3; NAME PATH HEADER_STATU ---------- -------------------- ------------ DUMMY_0000 /dev/sdg1 MEMBER
some time in the future the diskgroup runs out of space and you request another device from the storage or os team. once the device is ready you check if you can see it in ASM:
SYS@+ASM> select name,path from v$asm_disk where header_status = 'CANDIDATE'; NAME PATH ---------- -------------------- /dev/sdh1 /dev/sdh
perfect, a new device is available to extend the diskgroup:
SYS@+ASM> alter diskgroup dummy add disk '/dev/sdh1'; Diskgroup altered.
time goes on and the diskgroup runs out of space again. another dba checks if there are decives available to add:
SYS@+ASM> select name,path from v$asm_disk where header_status = 'CANDIDATE'; NAME PATH ---------- -------------------- /dev/sdh
cool, no need to request another device:
SYS@+ASM> alter diskgroup dummy add disk '/dev/sdh'; Diskgroup altered.
and bumm:
Errors in file .../admin/diag/asm/+asm/+ASM/trace/+ASM_arb0_2432.trc: ORA-15130: diskgroup "" is being dismounted ORA-15335: ASM metadata corruption detected in disk group 'DUMMY' ORA-15130: diskgroup "DUMMY" is being dismounted ORA-15066: offlining disk "DUMMY_0002" in group "DUMMY" may result in a data loss ORA-15196: invalid ASM block header [kfc.c:29297] [endian_kfbh] [2147483650] [10] [0 != 1] ORA-15196: invalid ASM block header [kfc.c:29297] [endian_kfbh] [2147483650] [10] [0 != 1] ORA-15196: invalid ASM block header [kfc.c:29297] [endian_kfbh] [2147483650] [10] [0 != 1] ORA-15196: invalid ASM block header [kfc.c:29297] [endian_kfbh] [2147483650] [10] [0 != 1]
What happened?: Two different people did not look exactly what they are doing
Mistake one: the system in question used udev rules for device persistence. when the os people adjusted the udev rules for the new device they did not exclude the whole disk:
KERNEL=="sdh*", OWNER="asmadmin", GROUP="asmdba", MODE="0660"
When this rule is applied ASM will see all the partitions of the disk as well as the disk itself:
/dev/sdh1 /dev/sdh
Mistake two: the dba which added the last disk did not recognize that the candidate:
SYS@+ASM> select name,path from v$asm_disk where header_status = 'CANDIDATE'; NAME PATH ---------- -------------------- /dev/sdh
..actually is the whole disk. so the whole disk was added to ASM after the partition (which spanned the whole disk) was added.
so, better look twice …
